When I met Dennis Yu about a year and a half ago, the first thing he told me to do was claim my Google Knowledge Panel. The second was to repurpose every one of my YouTube videos into articles. The panel part happened. I claimed it, I’ve since helped some of the world’s best dunkers claim theirs, and my confidence score on Google is sitting at 208 right now. The repurposing part is the one I quit on, and it took me until now to fix that.
Why I stopped the first time
Back then the workflow was ChatGPT and custom GPTs writing the drafts, then me going into WordPress by hand to paste everything in, set the slug, write the meta description, and do all the Rank Math optimization. I was trying hard to make every article actually good, and each one took me about an hour. That pace works for two or three articles. It does not work for a library like mine.
My main channel has 1.9K videos on it. The Dunk Talk Podcast channel has another 141, and 69 of those are full episodes. My digital marketing channel, the one this video lives on, has 44 more. Then there are the 8 podcasts I’ve been on as a guest. None of it was organized in a way that made repurposing easy, so after a while I stopped. There was higher value work in front of me, and an hour per article was a price I wasn’t willing to keep paying.
The inventory sheet came first
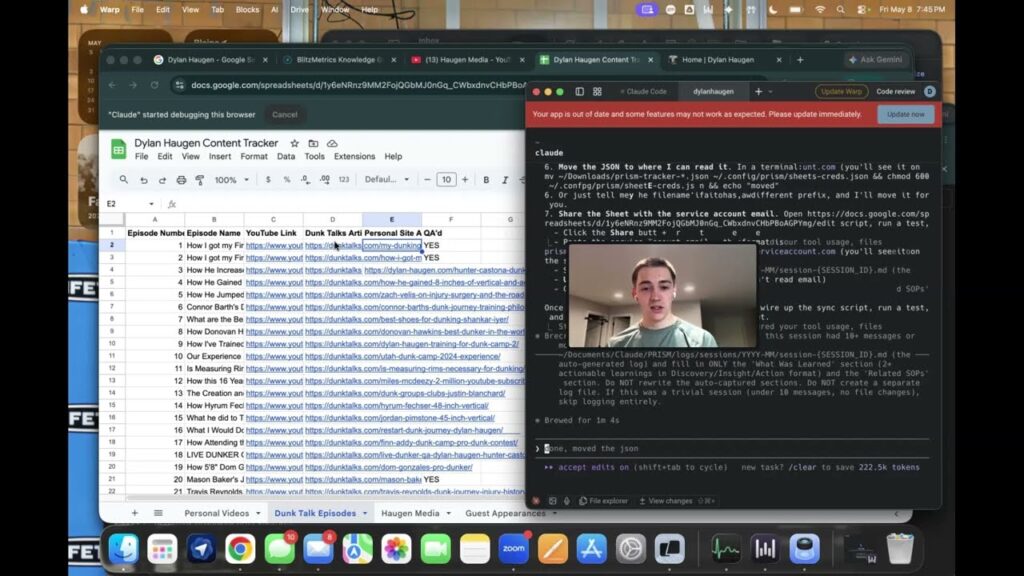
The system starts with a Google Sheet that Claude built by going through every channel and pulling every video into one place. Four tabs: Personal Videos, Dunk Talk Episodes, my digital marketing videos, and Guest Appearances. Each row has the video title, the YouTube link, the article link once it exists, and a QA’d column. The podcast tab also gets episode numbers, which makes it a lot easier to look at.
Out of everything, I marked 143 personal videos as worth repurposing, plus all 69 podcast episodes, the 44 marketing videos, and the 8 guest appearances. That’s 264 articles that are going to exist because of this system. I walked through how the tracker itself is structured in a video on the Local Service Spotlight channel if you want to copy the format, but honestly, you can just ask Claude to build it.
Teaching Claude to sound like me
The first two episode articles on dunktalks.com didn’t go straight to publish. I read them and talked to Claude about every section I didn’t like: this part isn’t how I would say it, this section should lead differently, this quote matters more than that one. Those corrections got saved as skills, so there’s now an actual knowledge base describing what my articles should look like.
That’s why the QA’d column exists. Early on I check everything. After enough reps, Claude already knows how to write them properly, and that column will matter less. The newest articles are already starting to look and sound like me, with the embedded episode, the meta description, the slug, and real quotes from the guests pulled straight out of the transcript.
Claude Code and an application password
More recently I moved this into Claude Code, the same setup I used when I built a prospect finder tool in 20 minutes. It takes all the feedback I’ve given it and edits the posts directly on WordPress through an application password, so nothing gets pasted by hand anymore. I’m also working on Google API access so it can update the tracker sheet on its own. This has been way faster and way better, and it’s a long way from the days when I was stitching automations together one tool at a time.
The part that matters: it has to be real
Google’s E-E-A-T guidelines have a second E for experience, and they added it because they knew AI tools would let people mass generate content. That’s exactly what this system doesn’t do. Claude isn’t making up what I would probably say about a topic. It takes the actual transcript from each video and repurposes it, pulling out the key details, the names, the numbers, and even direct quotes from the people in the video.
That’s also why this feeds my Knowledge Panel. Every article is corroborating information about me on a site I own, and it makes my relationships public. I interviewed Jordan Kilganon, the best dunker of all time, back on episode 47 of Dunk Talk. Google should be able to see that. When my panel recently disappeared, fixing my Wikidata brought it back, and we published the case study of that repair for anyone who wants the exact steps. The long game is this: hundreds of real articles all pointing at the same entity.
Do this with your own library
If you have videos sitting around, this is the best time there has ever been to do this. Have Claude inventory everything into a sheet, train it on your first few articles, and then let it run. It’s the same playbook we ran for Paul Ryazanov’s content pipeline. You can check your own confidence score with the Knowledge Graph Explorer we built, and the company-side breakdown of this whole build, the full pipeline on BlitzMetrics, walks through it step by step. And if you have a podcast, hit me up. I’d love to get on some more soon.